BlurHash Meets Metal: Supercharge Your App’s Image Loading Experience
BlurHash got a metal-powered upgrade. Instant previews, zero lag, and blazing-fast performance that shows what’s possible when image decoding meets GPU acceleration.


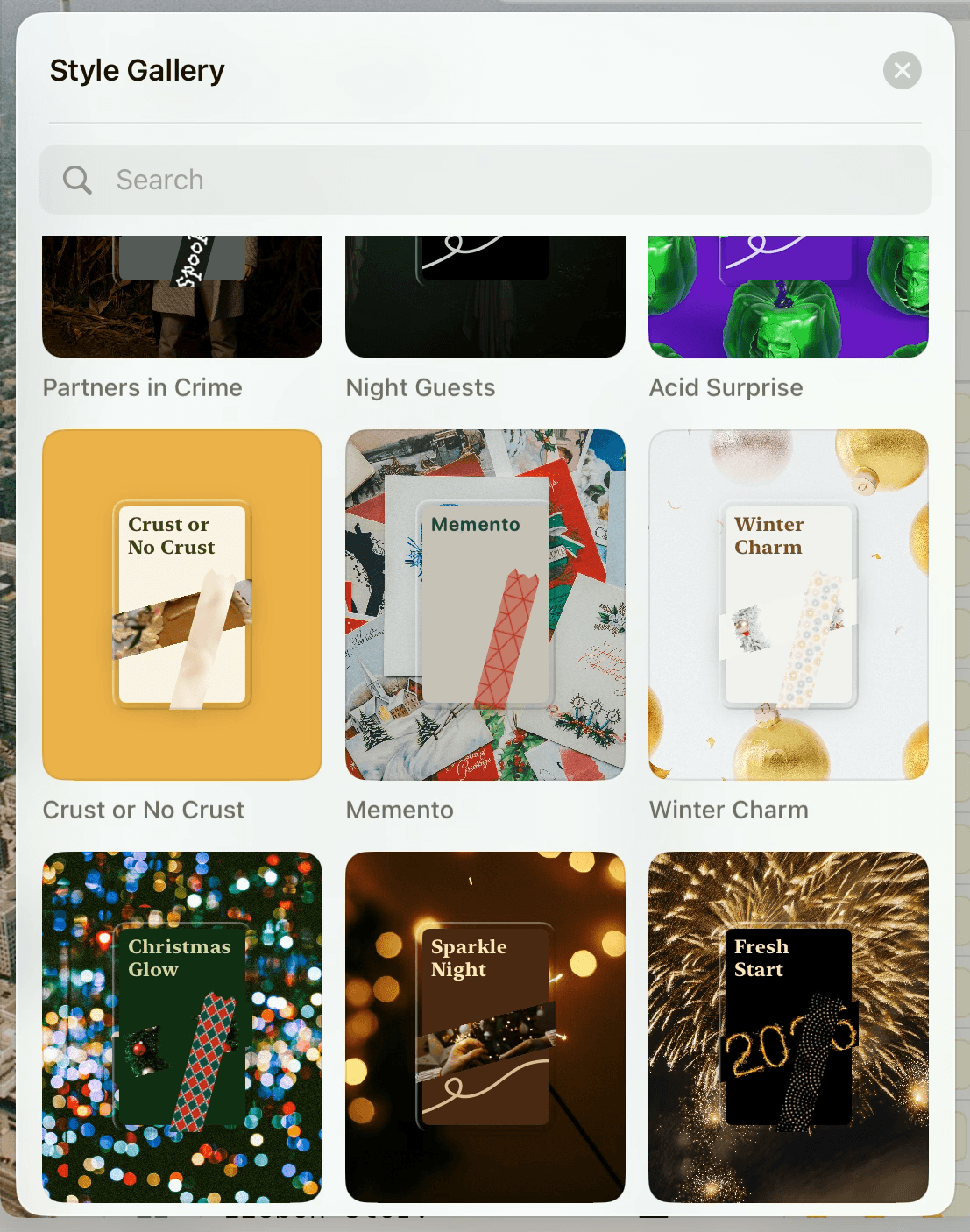
As a developer at Craft my job is to make our ideas a reality. That means bringing an exceptional level of care and precision to everything we build, whether it’s refining the smallest UI transition or optimizing image compression algorithms with GPU Compute Shaders. Because great design doesn't have to come at the cost of performance. With Craft v3 we released the Style Gallery, a sleek new feature which lets you choose from our curated list or your very own styles.
The Bottleneck: BlurHash at Scale
We rely on BlurHash, an ingenious algorithm developed by Wolt, to generate visually appealing placeholder images. BlurHash transforms large images into tiny strings, which can be transported alongside the download URL of the actual image. As your image loads, a placeholder is displayed and smoothly crossfades into the final downloaded image.

But when our Style Gallery grew to display as many as nine styles simultaneously, each with up to three placeholder images, BlurHash, running purely on a single CPU core, quickly became the performance bottleneck. This was noticeable during intensive scrolling session when you just couldn't quite find the right style for you.
Before diving deeper into BlurHash, I implemented a solution where the placeholder images would be generated simultaneously with the image download and inserted if they were finished before the image arrives. This resulted in complex multithreading code and you had to be very careful with race conditions. However, what bothered me more is that BlurHash was using all CPU resources; placeholder image generation should be lightweight and I felt like BlurHash was inefficient.
Style Gallery has been my favorite feature ever since I joined Craft back in January and I really wanted to see it shine. I wasn't satisfied yet, I wanted something faster. Much faster.
The Investigation: Under the Hood of BlurHash
The tiny string I talked about earlier is actually made up of two* things. First, the number of components. Second, the value of each component. BlurHash, likely taking inspiration from the JPEG compression algorithm, essentially decomposes your image into the combination of (up to) nine horizontal and nine vertical cosine waves each with a different weight, with the weights being the components in the string. To decompose the image, the algorithm goes over the entire image, performs a Discrete Cosine Transformation (DCT) and encodes the components into Base83.
*technically four, there are three different components: Maximum AC value, DC component, AC components
Each components’ weight is calculated on the entire image and there is no dependency between component.
This begs the question, this is a massively parallelizable image processing task, why is this not running on my GPU yet?
Enter Metal: Apple’s GPU-Powered Savior
Back in January I was implementing on-device inference for our local AI integration. The inference is done by MLX which is using Metal to achieve amazing performance and fully utilize the GPU. This has got me thinking, LLM inference is also parallelizable task, why can't I also use Metal to speed up BlurHash?
I dove head first into the Metal documentation and started experimenting. I wrote tests to make sure my enhanced encoding and decoding algorithms would match (or be within 5% of tolerance) the original implementation. Then I quickly begun experimenting by moving the heart of the algorithms into Metal Compute Shaders.
By rewriting critical encoding and decoding routines in Metal, initial benchmarks blew me away: encoding became over 200 times faster, and decoding improved even more dramatically. At first it was hard to believe. I had to delete the original implementation and save the decoded image to the disk to believe it actually ran!
And thus, MetalBlurHash was born.
MetalBlurHash: A Drop-in, GPU-Accelerated Solution
MetalBlurHash maintains complete compatibility with Wolt's original BlurHash implementation. It’s a drop-in replacement, easy integration, zero hassle. Switch the library, enjoy the performance benefits:
| Task | Original | MetalBlurHash | Speedup |
|---|---|---|---|
| Encode | 32.212s | 0.154s | 210x |
| Decode | 3.267s | 0.013s | 25x |
| MetalBlurHash is over 200 times faster than the original implementation |
| Task | Resolution | Components |
|---|---|---|
| Encode | 3648 × 5472 | 9x9 |
| Decode | 3840 × 2560 | 9x9 |
| Test Parameters (benchmarked on M1 MAX using XCTest performance testing) |
In our Style Gallery, MetalBlurHash instantly erased any lag, all while simplifying our implementation. We could now generate the placeholder image before we even started loading the actual image, no more need for debugging race conditions caused by simultaneous image loading.
One more thing
MetalBlurHash is available today, under a permissive MIT license.

⚠️ Limitations
MetalBlurHash will always return nil if Metal initialisation fails, prepare for this case too
BlurHash generation does not work in Widgets as Command Buffer execution is not allowed from background:
Execution of the command buffer was aborted due to an error during execution.
Insufficient Permission (to submit GPU work from background)
(00000006:kIOGPUCommandBufferCallbackErrorBackgroundExecutionNotPermitted)
How to Integrate MetalBlurHash into Your Project
It's as simple as: Using Swift Package Manager, replace BlurHash with MetalBlurHash in your project.
Yes, it's that easy.
If you would like to start using MetalBlurHash please refer to the documentation inside the repository.
Conclusion: Let Curiosity Drive Performance
What started as a desire to polish one of my favorite features turned into a deep dive into image processing algorithms and GPU acceleration. Along the way, I learned just how much performance potential can be unlocked by rethinking traditional bottlenecks and utilizing GPU compute.
It has never been easier to do hard things. With a well defined acceptance criteria, in this case the outputs of the metal algorithms being within the margin of error of the original outputs, you are able to leverage LLMs to make yourself a truly 10x engineer.
So go ahead, move things to the GPU. Experiment. Question the defaults. With the right tools and a bit of curiosity, you might just surprise yourself with what’s possible.
If you have questions regarding MetalBlurHash, hit me up at zsombor.szenyan@craft.do